Hiroki Naganuma
Please give succinct but precise answers.
1.
Standard neural networks and directed probabilistic graphical models are both typically represented using directed graphs. But what nodes and arcs represent differs. Explain these differences.
A probabilistic graphical model is a graphical representation of a probability distribution,
a network that describes causal relationships by nodes.
The purpose of NN is to learn the relationship between input x and output y conditional on the model parameters Θ,
and only point estimation is possible.
NN differs from graphical model definitely in that it is deterministic, i.e. not stochastic.
- 手書きメモ
- 確率グラフィカルモデルのOverview
- グラフィカルモデルの分類 (マルコフネットワーク・ベイジアンネットワーク)
- 確率伝搬法
- マルコフ連鎖モンテカルロ法
- 普遍分布と平衡分布
- ギブスサンプリング
- グラフィカルモデル
- ベイジアンネットワーク (条件付き確率を表現、条件付き独立かを判断できる) -> 伝承サンプリング(Ancestral sampling)
- マルコフネットワーク (積で同時分布を表現、ギブズ分布) -> MCMC(マルコフ・チェーン・モテカルロ)
- 観測変数より事後分布を求めるのが難しいので、MAP推定・周辺事後分布(or その推定量)・サンプリングが用いられる
- Burn-in:十分なサンプリングをした後に実際に使用するサンプリング点を取得する方法
- 複数のサンプル点を使用する場合は、それらの間に相関関係が発生しないように、十分にサンプリング間隔をあけたサンプル点を使用する必要がある
- チェインモデル(HMM)、ツリーモデル、グリッドモデル(特に、マルコフ確率場(MRF))
- ベイジアンネットワーク
- BN は,因果関係 (causality) を確率により記述するグラフィカルモデル(graphical model) の一種で、複雑な因果関係の推論を非循環有向グラフ(directed acyclicgraph: DAG)により表し、個々の変数間の関係を条件付き確率 (conditional probability) で表す確率推論のモデルである
- BN やその他さまざまな確率計算システムにおける近似計算技法として確率伝搬法 (belief propagation: BP) と呼ばれる近似計算法が広く利用されている(sum-product アルゴリズムとも呼ばれる)
- 明確な親子関係を課していないため,そのような微妙な(因果関係の判断が難しい)場合も考慮に入れてモデル化できるというのがマルコフ 確率場の一つの利点であり,そのため,現在のさまざまなパターン認識システム(画像理解システムなど)の設計の中核をマルコフ確率場に基づくモデルが担っている
- 決定論的なニューラルネットワーク
- 教師あり学習で最小二乗誤差を損失関数に選択した場合、これは出力データにガウスノイズが生じている場合における最尤推定をしているのと同等
- 最尤推定には”ある条件”のもとで推定として良いとされる諸性質(一致推定量であること、二次の漸近有効性を有すること等)が備わっている
- “ある条件”をニューラルネットワークは通常満たしていないため、そもそも最尤解に辿り着くこと自体を突き詰めても有用な解が得られる保証がない
- 最尤推定からベイズ推定まで
- ベイズ(事前)予測分布 と ベイズ(事後)予測分布
- 確率モデリングのための確率分布の式変形基本【ベイズの定理/グラフィカルモデル】
- 基本的な確率分布の式変形とグラフィカルモデルについて
- 同時分布とグラフィカルモデルの Graphical な表示

- 確率モデリングと事後分布、事前分布、超パラメータ
- 下記を観測データ XN による条件付き分布のことを事後分布と呼ぶ

- グラフィカルモデルの記述の仕方

- 1つ前の時刻に依存するモデルは1次マルコフモデルと呼ぶ

- 下記を観測データ XN による条件付き分布のことを事後分布と呼ぶ
- ベイズニューラルネットワーク基本
- 同時確率分布から深層学習への変遷
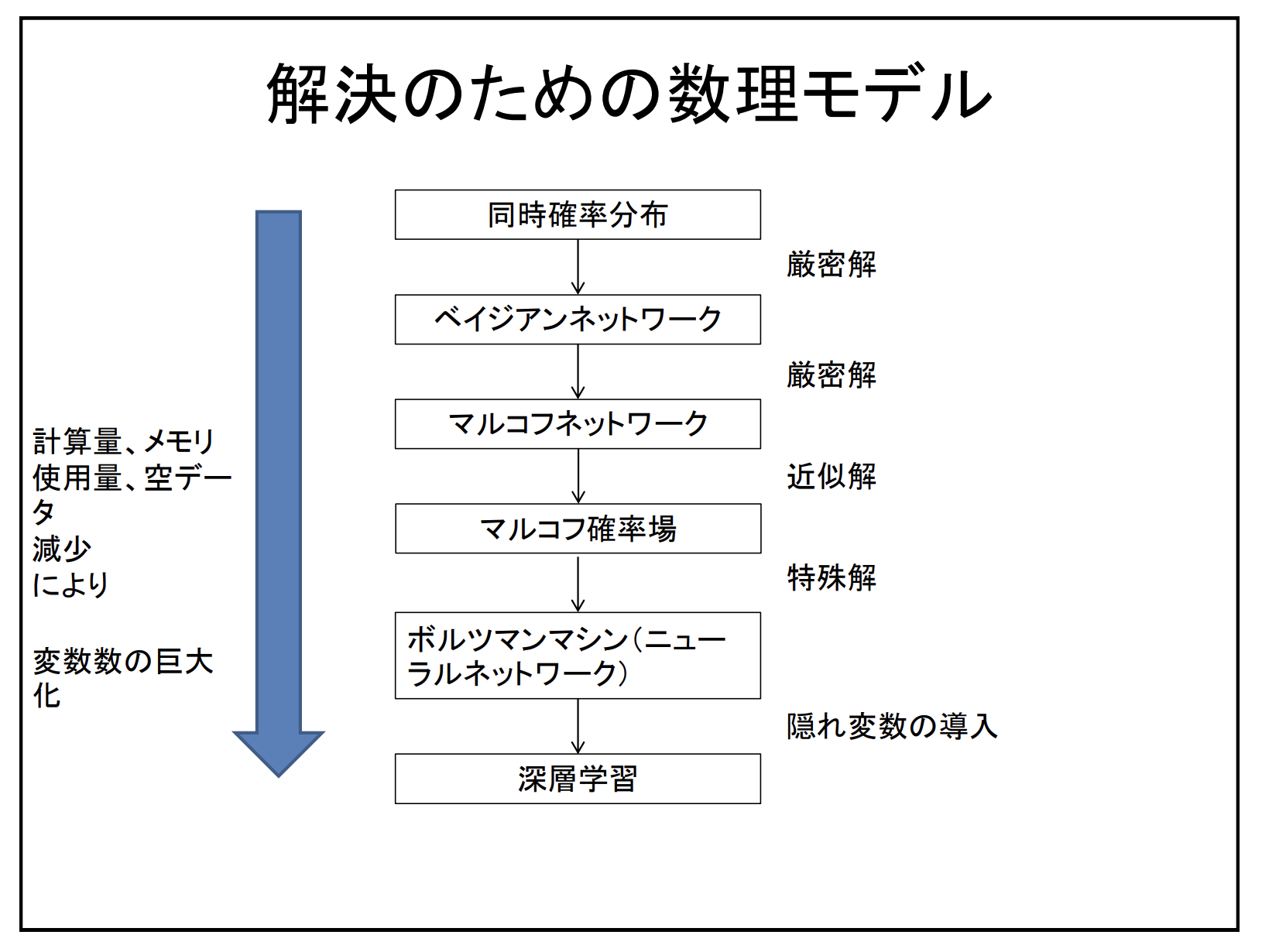
翻訳がちょっと変だけど、
-
Probabilistic Graphical Models 輪読会 の資料前半は、GMまでの前提知識
- NNはグラフィカルモデルではない、決定木なども
- 知識と推論の分離
- 結合分布を用意して、事後分布を計算できるようにする(確率的推論)
- 確率的グラフィカルモデルは、グラフを基本として高次元空間の複雑な分布をコンパクトに表現できる
- GMの三大要素は、表現・推論・学習
- 表現: 結合分布の構造、グラフ表現は明瞭かつ取り扱いが容易
- 推論: 事後確率を効率よく計算
- 学習: 相応しい予測をするためのパラメータ学習 (データ駆動な学習)
- 初期のベイジアンネットワークは家族間の遺伝子の継承という分野から派生
- 頻度主義と・主観的確率(繰り返し施行できない事象は頻度主義のパラダイムでは説明できない)
- 条件付き独立 (CI: Conditional Independence)
- チェビシェフの不等式: 期待値から外れた現象がどのくらいの確率で生じるかを見積もることができる便利な公式
- DAG (Directed Acyclic Graph) 有向かつ、非循環なグラフ、ベイジアンネットワークの表現の中心をなす
-
PDAG (部分DAG)、Chain Graphとも: 元のグラフから取り出した頂点間の辺の有無が元のグラフと一致、わかりやすい説明!

- Poly Tree: ループのない有効グラフ、無効グラフだったら forest
- Chordal 弦
- Probabilistic Graphical Models 輪読会 の資料後半は、ようやくGM
- 基本原理 (モジュラリティ、抽象化)
- 各ノードが確率変数、辺の欠如がCIの仮定を示す
- エッジに向きがあるときはベイジアンネットワーク(BN)、そうじゃなければ無向グラフィカルモデル
- BN = DGM (Directed Grahical Model) = Belief Network = Causal Network
- 無向グラフィカルモデル (UGM) = Markov Network - Markov random Field (MRF)
- MRFとしてはIzing Model などが有名:格子状のノードで、+1 or -1 をスピンの向きによってもつ、角格子状のスピンは隣接するスピンの値によって確率的に決定 (Gibbs 分布)
- 画像のノイズ除去などに用いられる
- しかし、これらの結合分布の計算量が大きい -> 因子分解で積の形に
- 特にBNはCIの仮定を置くことがKey
- グラフィカルモデル入門
- PRML8章 Graphical Model 一番読みやすい
- 制約ボルツマンマシン
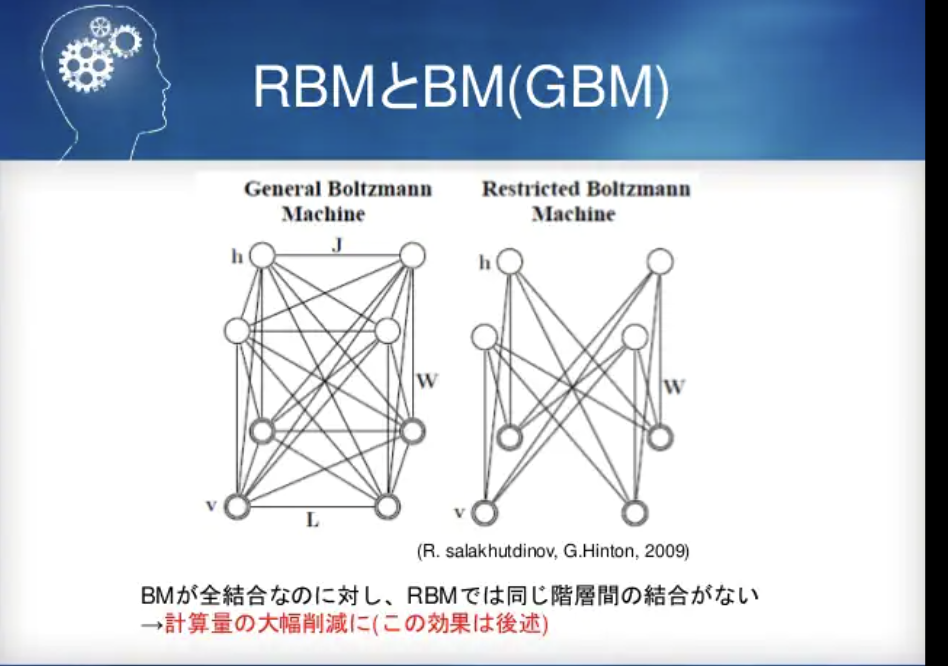
- Metropolis-Hastings algorithm: マルコフ連鎖モンテカルロ法の一つで、直接的に乱数の生成が難しい確率分布に対し、その確率分布に収束するマルコフ連鎖を生成する手法
- ergodic theory: ある力学系がエルゴード的(ある物理量に対して、長時間平均とある不変測度による位相平均が等しい)であることを示す、すなわちエルゴード仮説の立証を目的とする理論
- Gibbs Sampling は Metropolis-Hastings algorithm の特殊ケース(条件付き分布の導出が簡単な時)、RBM でも使う
- Contrastive Divergence (Gibbs Sampling を用いて、結合分布の計算を近似する、意外とMCMCみたいな感じで、サンプリング数1とかがいい、可視層と隠れ層を交互に更新していくイメージ?表現力向上のための二段構え、潜在的な表現を考えられるので、データの一部が破損してるとかにも対応できるかも?!)

- RBMは、訓練データの分布にRBMのパラメータをなるべく近づけようとしている
- RBM の 可視層と隠れ層を一層ずつ表現の獲得をやっていったのが Deep Belief Network
- 具体的には隠れ層の最上位層を入力としてロジスティック回帰を行なう、SVMとか線形回帰でも良い
- DBM (Deep Boltzmann Machine)は DBN を無向にして、表現力を上げてる(計算量は増える)、雰囲気上下から学習している
- RBM は可視素子ごとの相関を取らず、隠れそうが可視素子との相関を持ち、つまり抽象化された特徴を隠れそうが表現できるように -> 教師なし学習
- Dropout や正則化による Sparse化 (神経科学的な知見から)
2
Explain the differences between the following approaches (inductive principles) a) maximum likelihood, b) maximum `a posteriori (MAP); c) complete Bayesian treatment; when learning and using a parameterized model for prediction (e.g. for a classification problem).
Maximum likelihood estimation uses the likelihood function as the most plausibility of the data when the parameter Θ is given, and estimates Θ as a point by maximizing the likelihood. (A method of determining the parameter Θ so that the data at hand, Xn, is most likely to be generated.)
MAP estimation is a method of point estimating Θ that maximizes the posterior probability, which is proportional to the product of the likelihood function and the prior distribution given to maximum likelihood estimation, considering Θ itself as a random variable.
When there is not enough data, prior knowledge can be used to prevent bias.
Bayesian estimation is a method that considers the posterior distribution in the same way as MAP estimation, and determines Θ by calculating the expected value of the posterior probability instead of point estimation.
- 手書きメモ
- 最尤推定・MAP推定・ベイズ推定を比較する
- 最尤推定/MAP推定/ベイズ推定についてのメモ
- 最尤推定では尤度関数を最大にするパラメータを求める
- 最尤推定では事前分布が考慮されていないため、MAP推定では事前分布を導入して事後分布を最大化するようにパラメータを設定する
- MAP推定では事後分布を最大にするようにパラメータを設定するため事後分布の形状が考慮されていないため、ベイズ推定では事後分布をもとに期待値を算出することでパラメータを設定する?
3
The most common neural network training procedure typically corresponds to either a maximum likelihood or a MAP optimization. Explain in what sense it can correspond to MAP (give a specific example).
Maximum likelihood estimation by training data (e.g., using cross-entropy loss, L2 regularization, by backpropagation),
assuming that the initial values of the parameters θ follow a certain distribution with regularization, is MAP estimation.

4
Formalize mathematically the architecture of a basic deterministic auto-encoder (AE). Clearly define notations and variables used and what each represents. Express mathematically the optimization problem that is solved during its training.
- 猫でも分かるVariational AutoEncoder
- オートエンコーダー_Auto Encoder (Vol.21)
- AE は次元圧縮を行う手法 (勾配消失問題解決、過学習問題解決のため、ただしこれらの問題は近年 CNN とかのアーキテクチャで次元削減が組み込まれたので、その用途では使われなくなった)
- 他の応用例として、(1)学習データのノイズ除去 、(2)異常検知の異常個所特定 、(3)圧縮した特徴をもとにしたクラスタリング などの応用例がある
- AEの後半部分で生成モデルが作れる、VAEでは潜在変数を確率分布を使うことにしてる
- Mathworks オートエンコーダ(自己符号化器)
- 次元削減や特徴抽出を目的に登場しましたが、近年では生成モデルとしても用いられている
- オートエンコーダの前半部分は次元削減、特徴抽出の機能を獲得し、後半部分は低次元の情報をソースとするデータ生成機能を獲得します。
- 前半部分をエンコーダ、後半部分をデコーダと呼びます
- AE の種類
- 積層オートエンコーダ
- 畳み込みオートエンコーダ
- 変分オートエンコーダ
- 条件付き変分オートエンコーダ
- 積層AE

- VAE: 変分オートエンコーダは、生成モデルとして有名です。通常のオートエンコーダとの大きな違いとして、入力データを圧縮して得られる特徴ベクトル(潜在変数)を確率変数として表します。一般的にはN次元の潜在変数が、N次元正規分布に従うように学習します。これまでに紹介したオートエンコーダでは、次元削減後の特徴ベクトルには特に制約はありませんでした。そのため、特徴空間上でデータがどのように表現されているかはわかりません。しかし、VAEでは、ここに正規分布という制約を設けることでデータの潜在空間上での分布に連続性が生じ、似た潜在変数からは似たデータが生成されるようになります。

5
Similarly, formalize the architecture and training criterion being optimized in a variational auto-encoder (VAE).