Hiroki Naganuma
Context
- Local SGD は、分散深層学習において、バッチを増やす、データ並列の文脈で提案された手法
- ベースラインは DDP (Distributed Data Parallel)
- 2024 年 7 月時点で、この文脈を一番汲み取っているのは “Asynchronous Local-SGD Training for Language Modeling (2024, Google DeepMind)”
- この論文の関連研究を中心に調査をする
重要人物 (更新途中)
-
- EPFL -> CISPA Helmholtz Center
- Local SGD の元論文の著者(単著)
-
- McGill -> FAIR Montreal
- SlowMo, Buffer 等を提案
-
- NYU -> UofT -> Google Brain MTV -> DeepMind London
- DiLoco, Async DiLoCo の著者
-
- UChicago -> FAIR -> DeepMind NYC?
- DiLoco, Async DiLoCo の著者
Original Paper
LocalSGD / Local SGD Converges Fast and Communicates Little

- arxiv
- EPFL, Sebastian U. Stich / ICLR2019
概要
- モデルを特定周期 H で平均化するのみ、Optimizer State の sync などをしない
- 平均化周期 H が大きすぎると損失の収束が遅くなる
- Async version も提案されてるけど使われてない
Post Local SGD / Don’t Use Large Mini-Batches, Use Local SGD
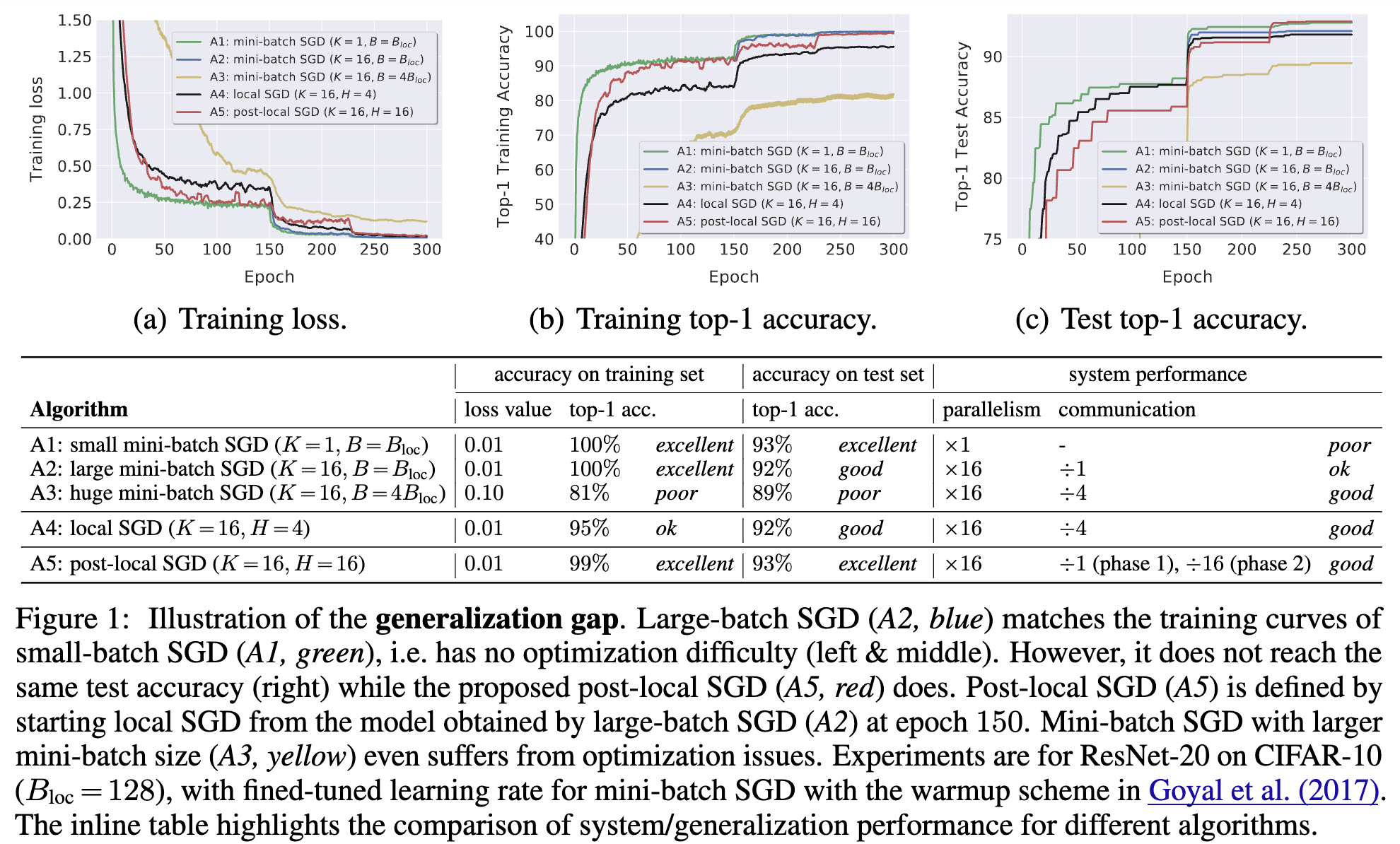
- arxiv
- EPFL, Sebastian U. Stich / ICLR2020
概要
- LocalSGD の後続研究
- 学習序盤は DDP で後半から Local SGD を適応するのが有効
- LocalSGD のハイパラの ablation study もやってる

Extrapolation for Large-batch Training in Deep Learning

- arxiv
- EPFL, Sebastian U. Stich / ICML2020
概要
- 前提
- Large Batch 学習における汎化性能の劣化が知られている
- ノイズを導入するような方法があるが、モデル特有のノイズや微調整が必要になることが多い
- そのために、計算効率の良い外挿(外勾配)を用いて、最適化の軌道を安定化させながら、鋭い極小値を回避する平滑化の効果を得ることを提案
- 実証方法
- 理論
- 収束性を証明
- 実験
- ResNet
- Use LM (LSTM, Transformer) for evaluation
- 理論
後続の研究
DiLoCo: Distributed Low-Communication Training of Language Models
- arxiv
- Google DeepMind / 2023 / ICML2024 Workshop
概要
- DiLoCo = FedAve + AdamW(inner)+Nesterov(outer)
- Robust on no-IID set as well
- DiLoCo use 500 as H (inner update) / is this because of LLM or this algorithm?
Asynchronous Local-SGD Training for Language Modeling
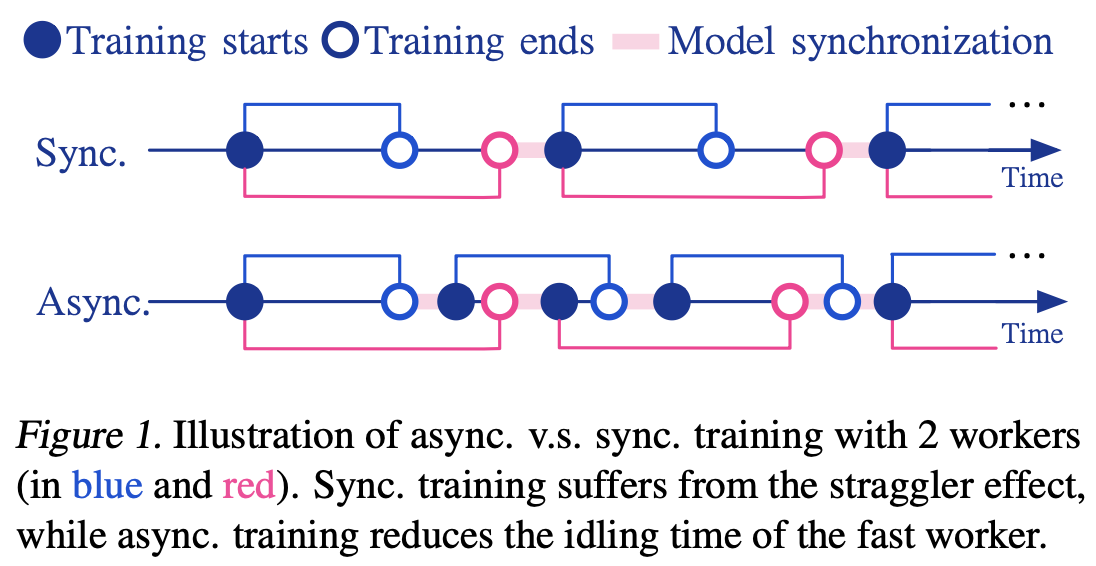
- arxiv
- Google DeepMind / 2024 / ICML2024 Workshop
概要
- 目的
- Async の Local SGD における stale gradient problem の解決
- 貢献
- Delayed Nesterov Momentum Update
- ワーカーから送られてくる擬似勾配をリアルタイムで処理するのではなく、一定期間蓄積して平均化する必要
- これにより、個々の勾配のばらつきを抑え、より安定した更新を行う
- Dynamic Local Updates
- 事前にワーカーごとのスピード計測をして、step 数を worker 間で違うものを(optimal なものを)設定する
- Grace Period を設定し、その間に Sync できるものだけ Sync
- Delayed Nesterov Momentum Update
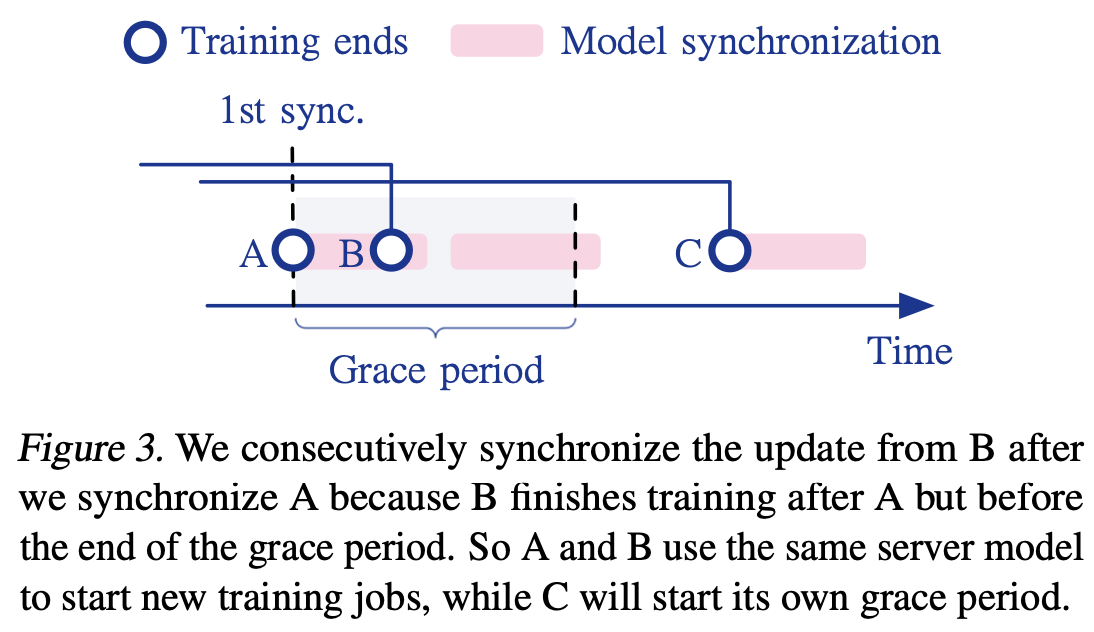
実験結果
- C4 dataset を 150M パラメータのモデルで学習して検証
- [Figure2]
- Async Local SGD は DiLoCO より劣る (Perplexity の点で)
- 以下二つを使うことを提案
- Delayed Nesterov (DN): 安定化
- Dynamic Local Updates (DyLU) : 高速化
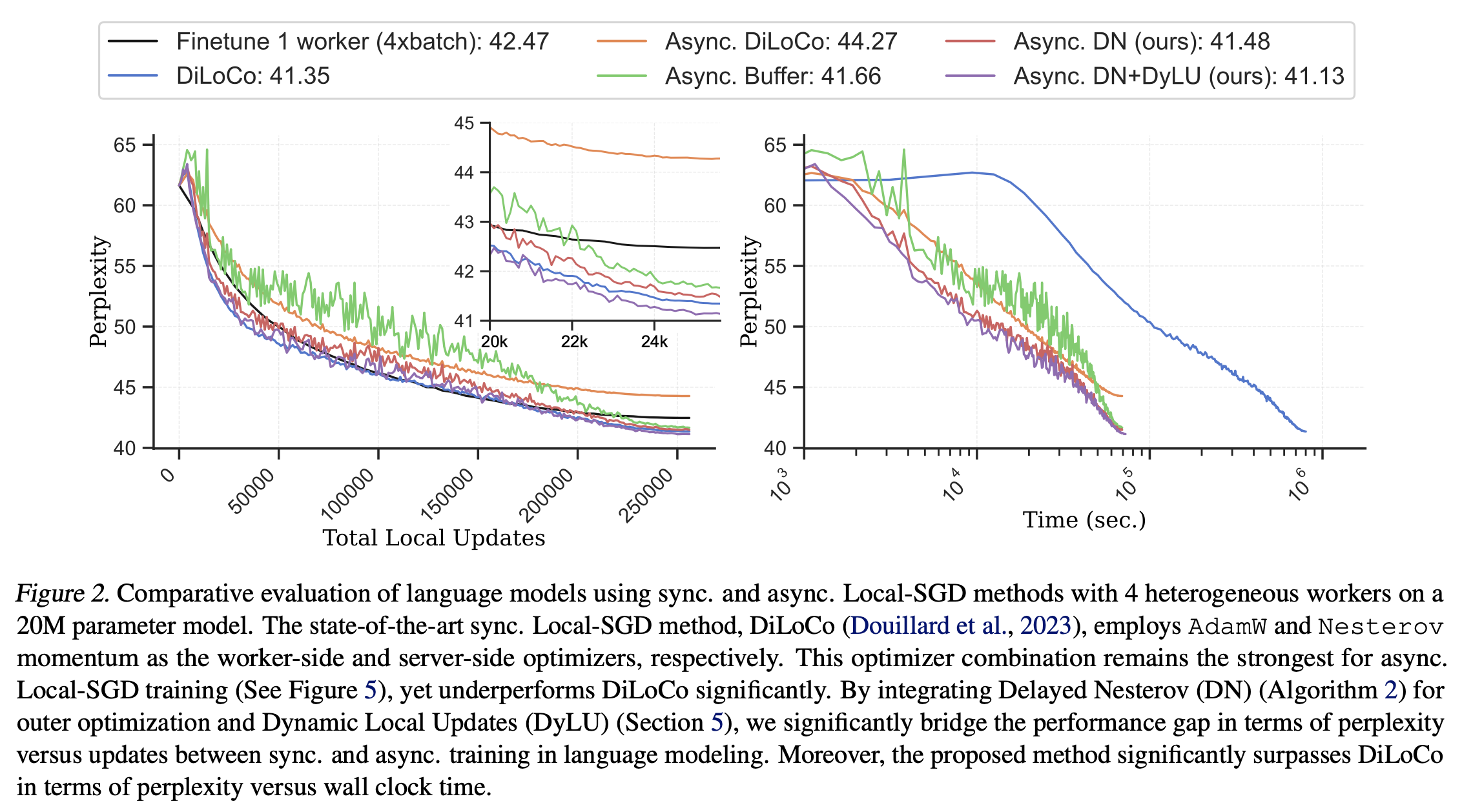
Findings
-
[Figure5]
- AdamW + Nesterov が一番良い
-
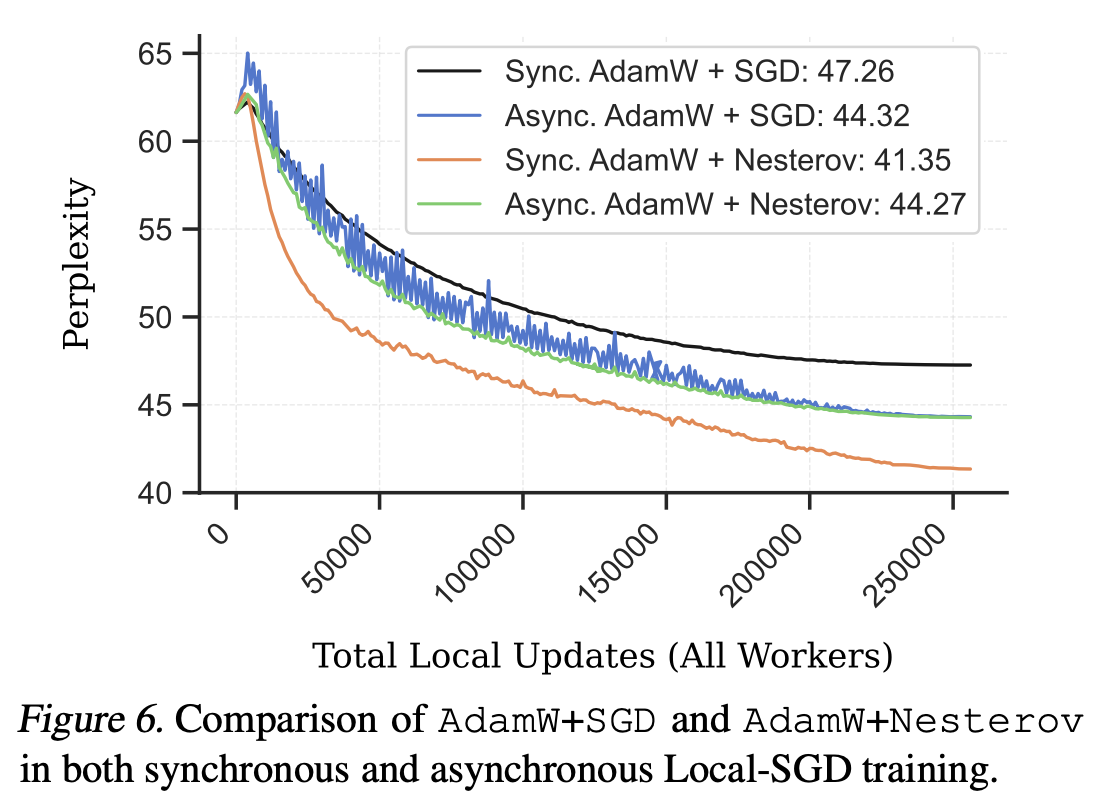
[Figure6]
- AdamW+SGD の場合は非同期の方が、perplexity が良い
- AdamW+Nesterov が一番性能がいい
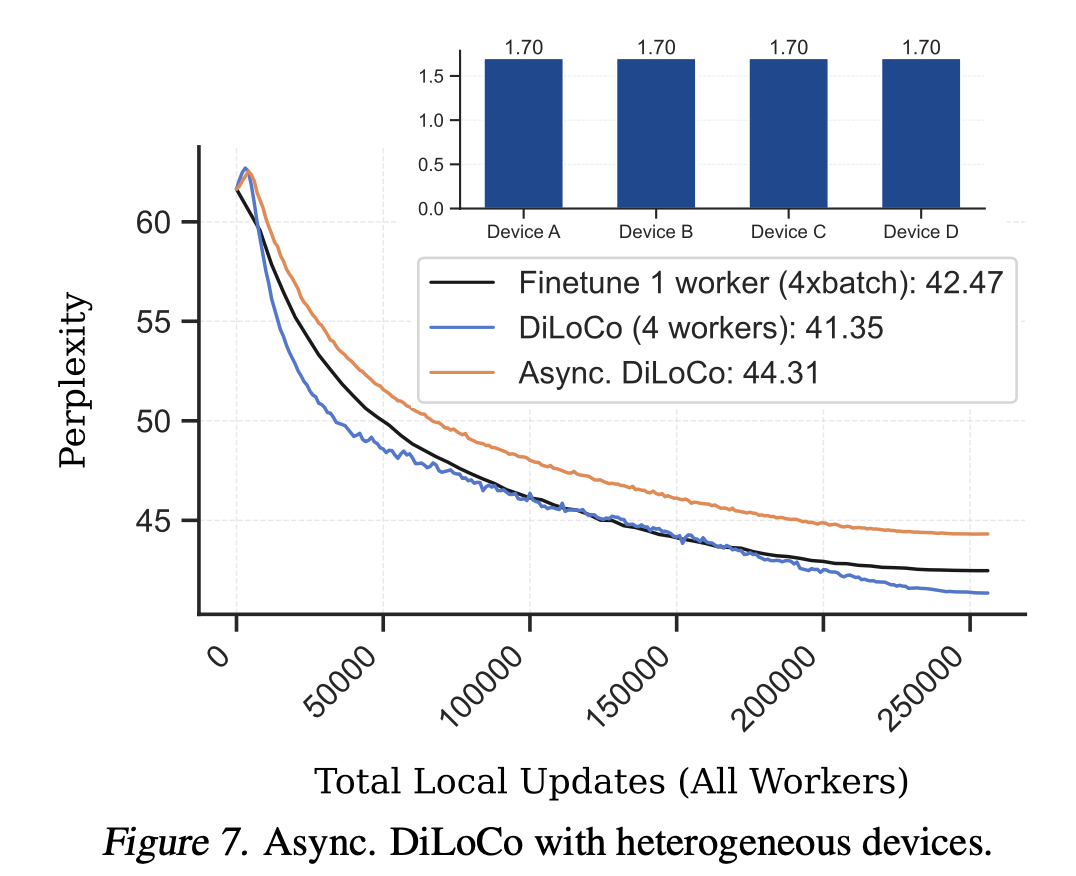
- [Figure7]
- 非同期の DiLoCo は同期バージョンに比べて大幅に遅れをとる
- これは、同時更新を順次適用することによる固有の遅延が、パフォーマンスの大幅な低下を引き起こすことを示唆
- [Figure8]
- Delayed Nesterov (DN)以外の先行研究での方法の検討、Poly Thres とか、Buffer (Federated learning with buffered asynchronous aggregation / Mike Rabbat 2022)とか
関連研究
-
Local-SGD と分散最適化 Local-SGD は、通信頻度を減らすために設計された特定の分散最適化技術です(Stich, 2018; Zhang et al., 2016; Bijral et al., 2016; McDonald et al., 2010; Coppola, 2015; Zinkevich et al., 2010)。Local-SGD の核心原理は、各ワーカーがグローバルな同期を行う前に複数のローカルトレーニングイテレーションを実行することです。この技術は後にフェデレーテッドラーニングの設定に適用され、通信オーバーヘッドを削減することを目的とした FedAvg 法(McMahan et al., 2017)が開発されました。Local-SGD とは異なり、フェデレーテッドラーニングはユーザーのプライバシー問題にも対処し、通常は異質なデバイスを含みます。通信オーバーヘッドをさらに最小限に抑えるために、FedOpt は SGD モメンタムや Adam のような適応的最適化手法を統合しています(Reddi et al., 2020)。しかし、ワーカーの異質性が増すと、収束速度がしばしば悪化します。SCAFFOLD(Karimireddy et al., 2020)や MIME(Karimireddy et al., 2021)などの手法は、異質な環境にこれらの手法を適応させるために導入されました。
-
非同期トレーニング 非同期トレーニングは、同期分散最適化において観察される「遅延ワーカー効果」を軽減するために開発されました。この効果では、学習効率が最も遅いワーカーによって制約されます(Koh et al., 2006; Recht et al., 2011; Dean et al., 2012; Lian et al., 2015; 2018; Diskin et al., 2021b)。非同期最適化における重大な課題は、更新遅延により発生する古い勾配問題です。この問題は、最新のモデルに古い勾配を適用する際に発生します。非同期 SGD with delay compensation(Zheng et al., 2017)は、古い勾配を用いて真の勾配を近似することでこの問題に対処します。非同期手法はフェデレーテッドラーニングの文脈でも探求されています(Xie et al., 2019)。この課題にもかかわらず、非同期トレーニングは言語モデルにも成功を示しています(Diskin et al., 2021b)。
-
言語モデリングのための Local-SGD Local-SGD(または FedAvg)の概念は、以前から言語モデリングの領域で応用されています。クロスデバイスフェデレーテッドラーニングは、例えば、言語モデルの事前学習や微調整に利用されています(Hilmkil et al., 2021; Ro et al., 2022; Ryabinin et al., 2021; Diskin et al., 2021a; Presser, 2020; Borzunov et al., 2022)。最近では、DiLoCo が Local-SGD の手法を拡張し、より大規模な言語モデルに対応し、具体的には AdamW + Nesterov モメンタムを InnerOpt + OuterOpt の組み合わせとして提案しています。非同期の設定では、FedBuff(Nguyen et al., 2022)アルゴリズムはクライアントからの擬似勾配をバッファリングし、十分な数の擬似勾配が蓄積された後にサーバーモデルを更新します。TimelyFL(Zhang et al., 2023)は、より遅いデバイスがモデルの一部のみをトレーニングすることを許可することで非同期性を削減することを目指しています。
Futurework
- この論文では収束解析や、なぜうまくいくかが、adhoc にしか検証されていない
Distributed Deep Learning In Open Collaborations
- arxiv
- Yandex, Vector, Hugging Face / NeurIPS2021
概要
- LM の設定で、非同期でも分散深層学習がうまく行っている例として紹介されている (Async DiLoCo の論文で)
貢献
- DeDLOC は非同期パラメータ更新(DPU)を利用しています。これは、勾配計算と通信を並行して実行できる技術であり、1 ラウンドの遅延の代償を伴いますが、様々なモデルにおいて収束時間を改善する効果
- DPU の導入により、各ピアが異なる速度で勾配を計算し、必要なバッチサイズに達するまで他のピアと通信せずに勾配を蓄積します。これにより、ネットワークの遅延やハードウェアの異質性に対処
- 非同期トレーニングの一貫性を保つために、DeDLOC は固定されたハイパーパラメータを用いた同期データ並列トレーニングを行います。これにより、各ピアが自分のペースで勾配を蓄積し、全体のバッチサイズに達したときにのみ勾配を交換して最適化ステップを実行
- グローバルモデルの更新は、各ピアが目標バッチサイズに達した時点で行い、全てのピアが同時に同期されるわけではありませんが、各ピアが一定のタイミングで最新のグローバルモデルを受け取ることになる
SlowMo: Improving Communication-Efficient Distributed SGD with Slow Momentum
- arxiv
- Mike Rabbat / Meta Montreal (ICLR2020)
- CMU の Jianyu Wang が Intern で行なったワーク
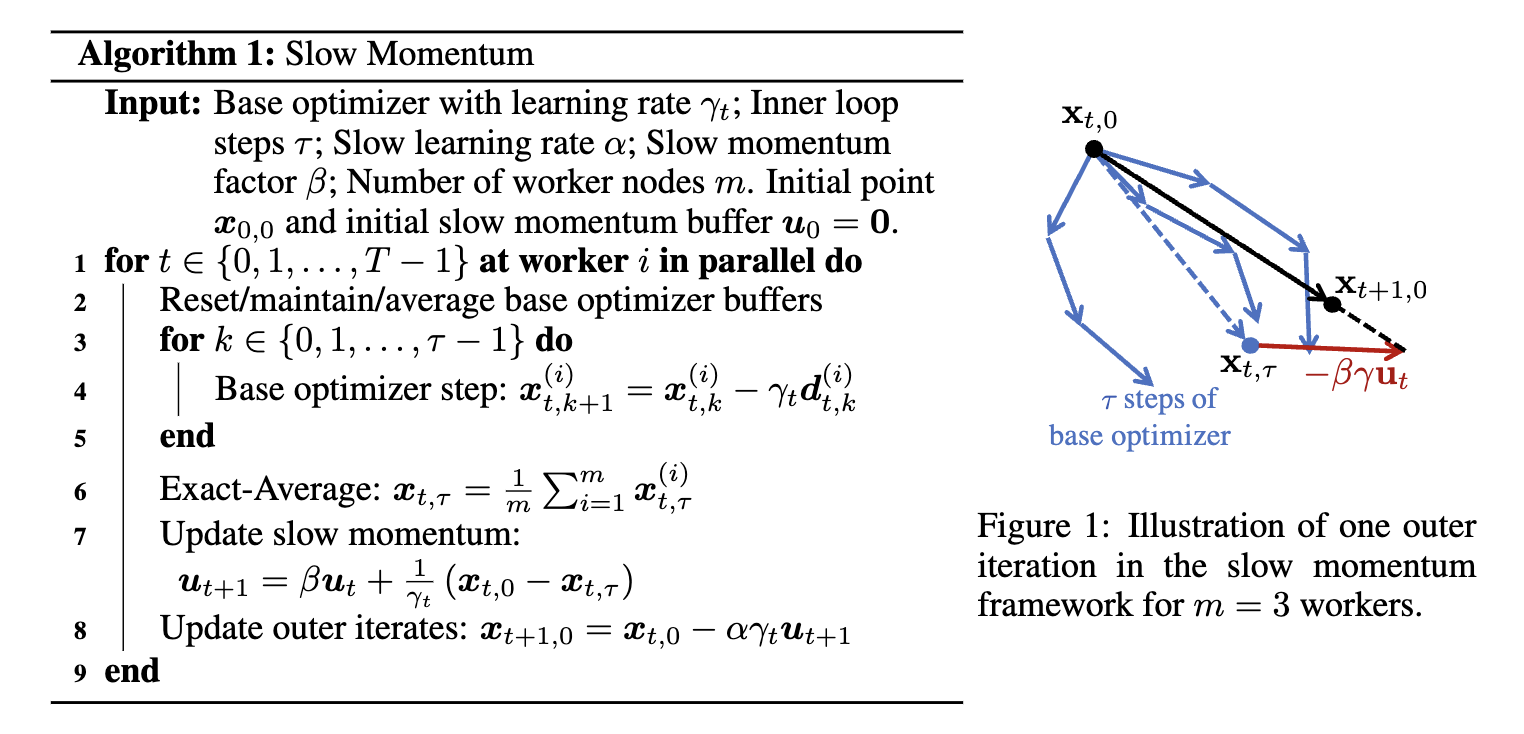
概要
- SLOWMO は、Local SGD や分散型の Stochastic Gradient Push(SGP)などの基盤アルゴリズムの上に構築
- 複数のローカルステップ後にパラメータを平均化し、モメンタム更新を行う
- 通信効率を維持しながら最適化性能と汎化性能の向上を目指す
- 具体的には、BMUF(Block-wise Model Update Filtering)に着想を得て、複数のローカルステップ後にパラメータの同期とモメンタム更新を行う
LocalSGD との違い
- SlowMo は Momentum SGD を使ったオプティマイザ状態(モメンタムバッファ)も同期する Local SGD と捉えられる
- LocalSGD と同様に、一定の回数の SGD ステップごとにパラメータを平均化しますが、それに加えてモメンタムバッファを同期
- 通信オーバーヘッドは LocalSGD よりもわずかに増えますが、その分精度の向上を確認
- 収束保証 (なので AISTATS に出されてる?)
- BMUF および Lookahead オプティマイザに対する初の理論的収束保証も提供されており、非凸関数に対する収束性も証明
- SLOWMO は LocalSGD よりも強力な理論的収束保証を提供し、非凸関数に対する収束性も証明
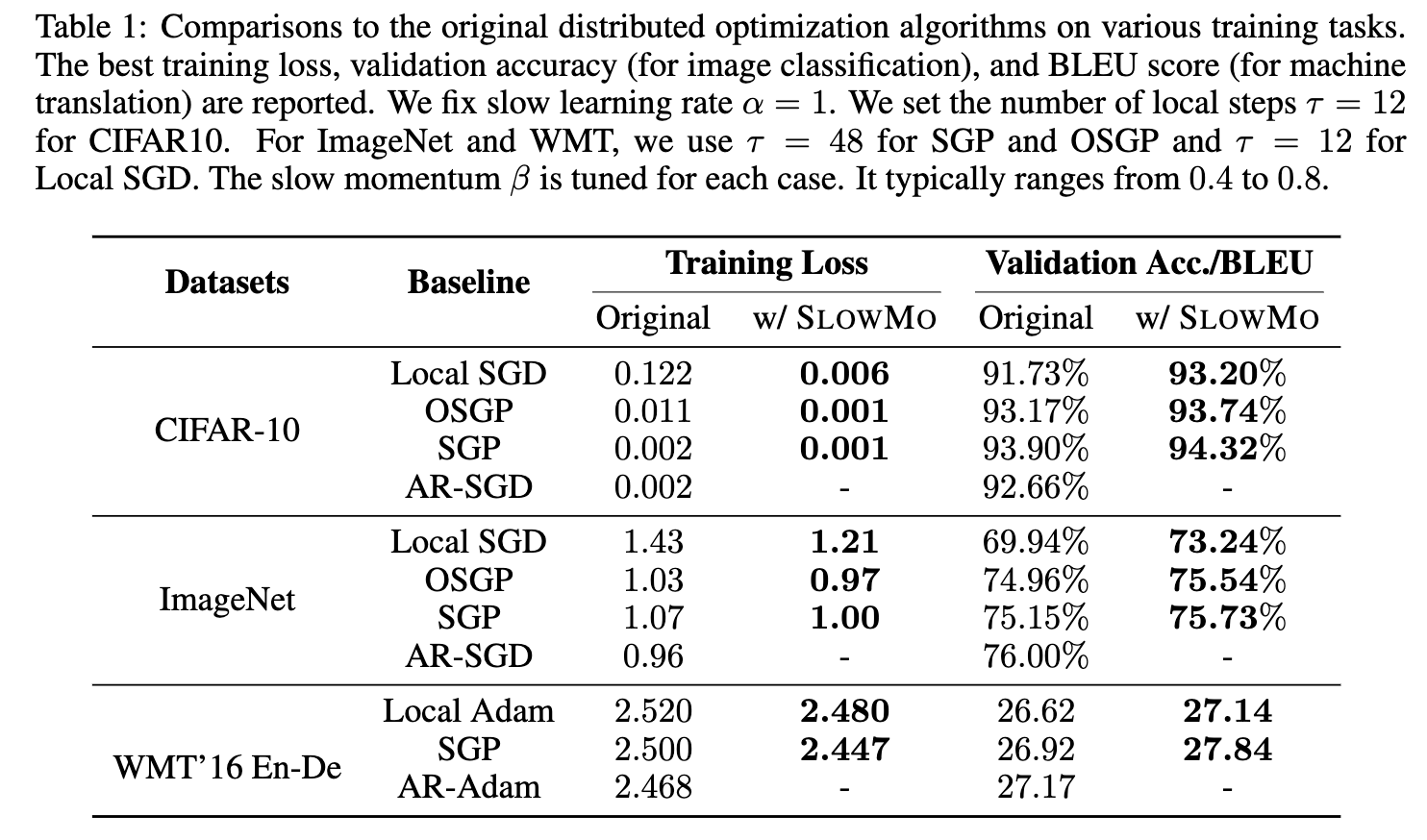
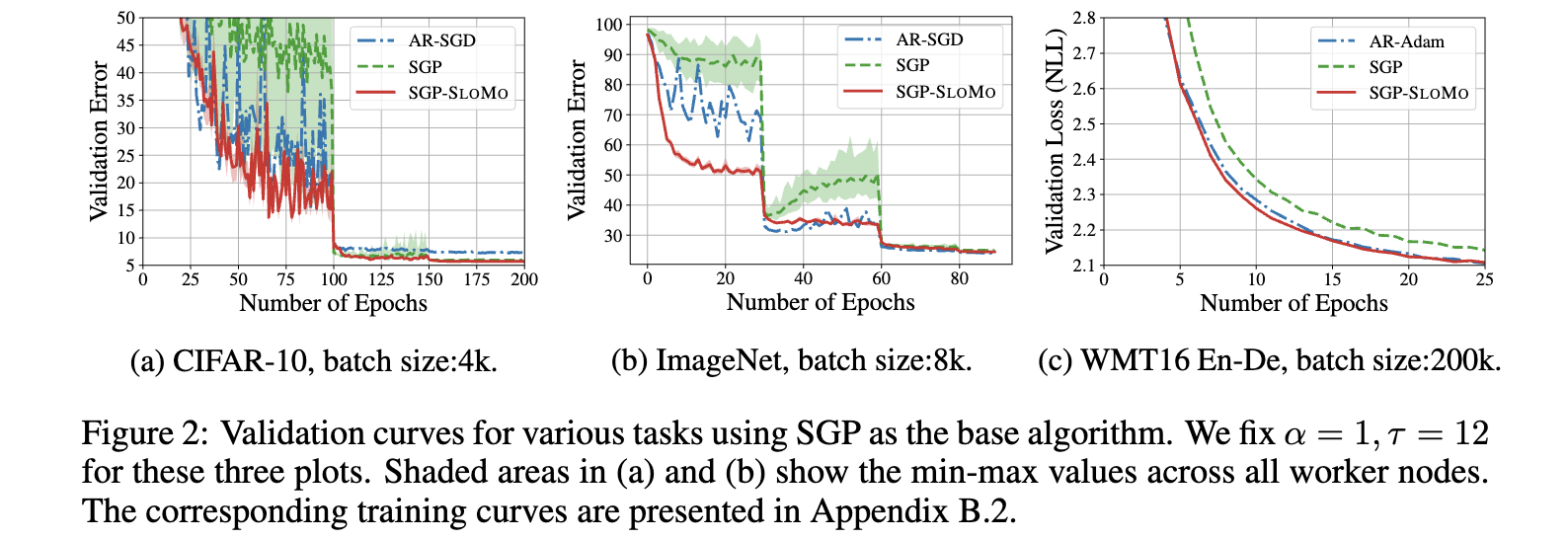
検証
- 結果
- SLOWMO を適用することで、一貫して基盤アルゴリズムの性能が向上することを確認
- 実験設定 (そんなに大規模ではない)
- CIFAR-10 および ImageNet を用いた画像分類タスク
- WMT’16 En-De を用いた機械翻訳タスク
疑問
- Q: 通信オーバーヘッドを削減するための分散平均化手法(例:ゴシップアルゴリズム)とは?
- A: “Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication” に示す(このブログの下の方)
Communication-efficient SGD: From Local SGD to One-Shot Averaging
概要
本論文は、分散環境における確率的勾配降下法(SGD)の通信効率を改善するために、Local SGD を発展させ、通信回数を大幅に削減する新しいアプローチを提案しています。
これまでの研究との違いや新規性
従来の研究では、Local SGD は通信頻度を高めることで収束速度を向上させることが示されてきましたが、依然として通信回数が増加するため、並列化の効果が減少するという課題がありました。 本研究では、イテレーション数が増加するにつれて通信頻度を減少させる新しい Local SGD 手法を提案し、総通信回数を最小限に抑えながらも収束速度を維持することに成功しました。 また、従来の手法では収束率が T に依存していましたが、本研究では通信回数が T に完全に依存しないことを示し、これまでにない通信効率を達成しています。
Fedrated Learning の文脈
- Local SGD は Fedrated Learning の文脈の FedAve に一致する(特定の条件下で)
FedAve(Federated Averaging)
Local SGD との違い
- 同期の頻度:
- FedAvg は、各クライアントが数エポックのローカルトレーニングを行った後に同期
- LocalSGD は、各ワーカーが指定されたローカルステップごとに同期
FedOpt(Federated Optimization)
- FedOpt は、FedAvg の平均化戦略に代わる、またはそれを補完する形で、中央サーバー上でより複雑な最適化アルゴリズムを使用
- 具体的なプロセス
- 各クライアントは、自身のローカルデータセットを用いて、数エポックのローカル SGD
- 各クライアントは、ローカルトレーニングの結果として得られたモデルの更新情報(例えば、勾配やモデルパラメータ)を中央サーバーに送信
- 中央サーバーは、受信したローカル更新情報を用いて、より洗練された最適化アルゴリズム(例えば、Adam、Adagrad、RMSprop など)を適用し、グローバルモデルを更新
Locally Adaptive Federated Learning

- arxiv
- Nicolas Loizou and Sebastian U Stich (Arxiv 2023)
概要
- FedSPS を提案
- 背景
- 従来の適応型 Federated Learning(例:FedAdam や FedAMS)は主にサーバー側の適応性に注目
- クライアント側の適応性については十分に検討されなかった
- いくつかの手法(例:Local-AMSGrad や Local-AdaAlter)はクライアント側の適応性を考慮しているが、通信ラウンドでステップサイズを集約するため、すべてのクライアントで同じステップサイズを使用
- 貢献
- 提案手法である FedSPS およびその減少版である FedDecSPS の収束性を理論的に解析
- i.i.d.および non-i.i.d.の両方のケースで、提案手法の最適化性能と汎化性能を実験により検証
Layer-wise and Dimension-wise Locally Adaptive Federated Learning
- arxiv
- Cognitive Computing Lab Baidu Research / (UAI2023)
概要
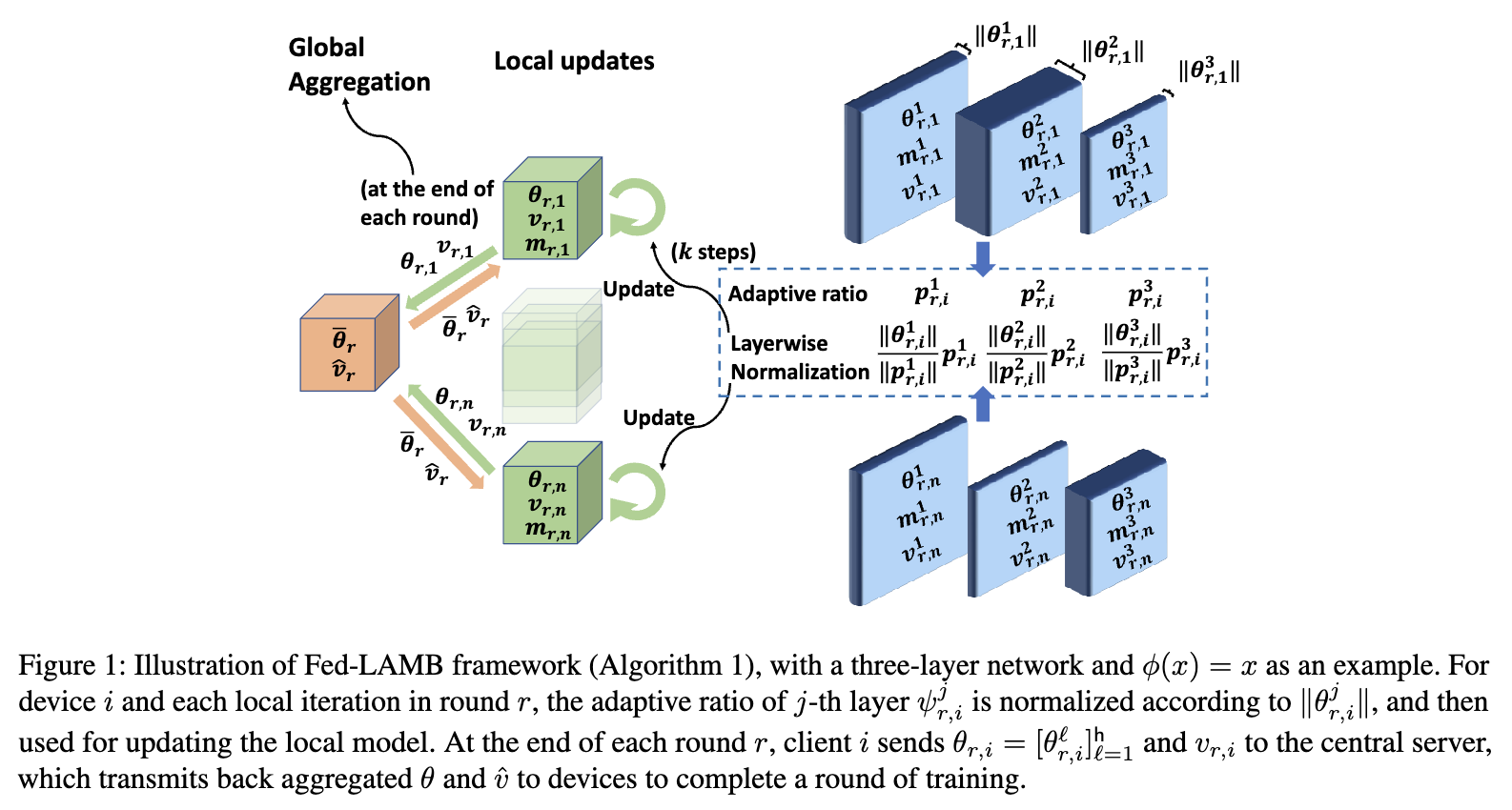
- Fed-LAMB を提案
- 背景
- FL 研究では、Adam や AMSGrad のような次元ごとの適応的勾配法が多く採用
- 提案
- しかし、本研究は初めて層ごとの適応性を FL に導入
- 各層の重みに依存した学習率調整を行うことで、収束速度をさらに向上
- 実証
- 理論
- Fed-LAMB と Mime-LAMB の収束解析
- 最先端の適応的 FL 方法と同等の収束率を持つ
- 実験
- IID データおよび非 IID データの両方の設定で実験
- 提案手法が多様なデータ分布に対して効果的であることを示した
- 収束速度が速く、汎化性能が優れている
- 理論
Federated Learning with Buffered Asynchronous Aggregation
- arxiv
- John Nguyen, Mike Rabbat / Meta Montreal (AISTATS2022)
概要
- FedBuff と呼ばれる新しい同期型と非同期型の FL の利点を組み合わせた Federated Learning 学習フレームワークの提案
- 従来の問題
- 従来の同期型 FL は、並列で訓練できるクライアント数が数百に限られており、それ以上のスケーリングが難しい
- 非同期型 FL はこの問題を軽減しますが、個々のクライアントの更新を集約する際にプライバシーが低下
- Buffered Asynchronous Aggregation
- クライアントの更新をバッファに一時的に保存し、一定数(K)の更新が揃った時点でサーバがモデルを更新
- 理論的解析も行ってる
- 実験は CelebA、Sent140、CIFAR-10 の 3 つのデータセット
その他の関連研究
Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication
- arxiv
- Sebastian U. Stich / EPFL (ICML2019)
概要
- 数学系の論文、実験も ToyModel で行なってる
- Gossip アルゴリズム (Choco-Gossip):
- 特徴:
- 情報が中央のノードからの一括放送ではなく、隣接ノード間での局所的な通信を通じて伝播される
- 通信ボトルネックを回避しつつスケーラビリティを向上させる点が特徴
- 利点:
- 中央ノードの通信ボトルネックを回避し、スケーラビリティが向上
- 圧縮通信をサポートし、低精度の通信でも線形収束を実現
- 特徴:
Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering
-
MSR Asia (ICASSP2016)
- BMUF(Block-wise Model Update Filtering) を提案
- Data Parralel の階層的な手法
- データを block に、その中でさらに split に分割し、GPU に割り当て
- split 内でまずモデルを平均化し、その後に block で平均化するようなことをする
- momentum とかを使ってモデルを平均化することで急激な変化を防ぐ