Hiroki Naganuma
Part IV [25 points]: Monte Carlo and Automatic Differentiation
Monte Carlo
Reference
- 密度比推定の手法と応用
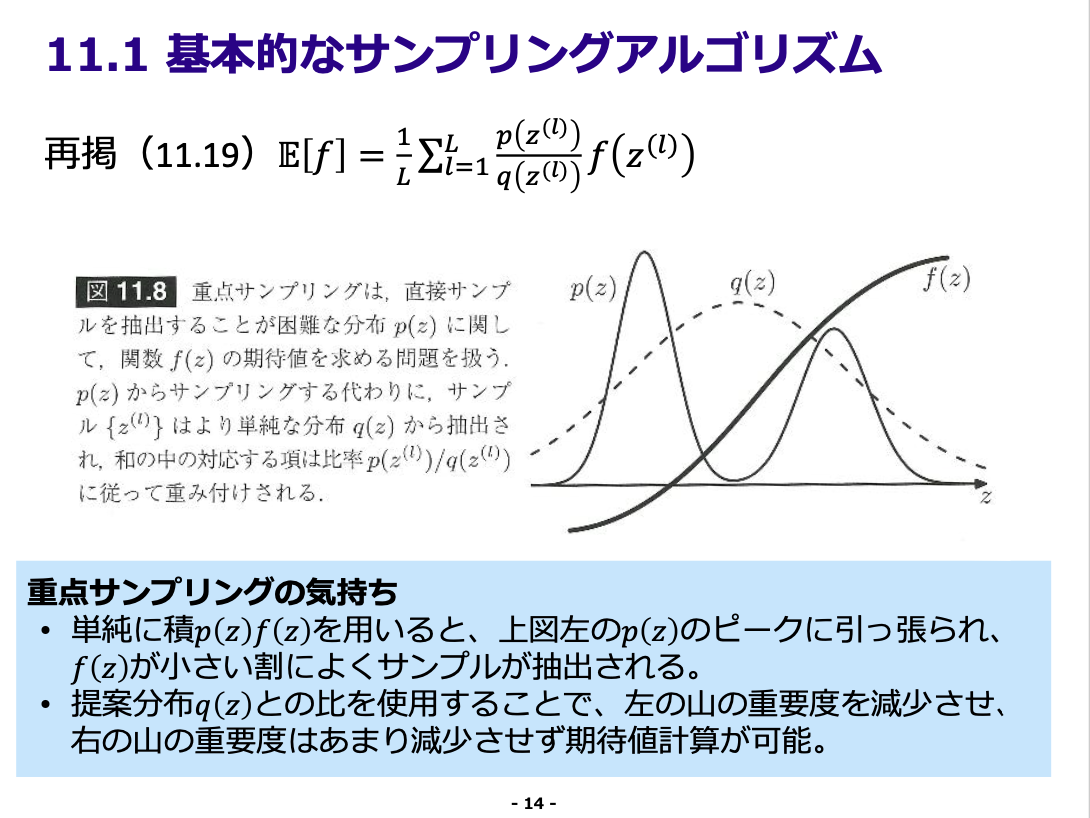
- 重点サンプリング (Importance Sampling)
- 重点サンプリング (1)
- 重点的サンプリング, 神戸大資料
- singular point, Mathematics, technologies, weblog, and my lifelog, サンプリング

PRML 11 章
- 第11章 サンプリング法
- 目的は「ある想定した分布」に従う乱数を発生させること(サンプリングすること)
- すなわち分布を再現すること

- 逆関数法 -任意の確率分布に従う乱数を生成する-
- 逆関数法一番納得感ある




- 11. Sampling Methods
- 基本的なサンプリングアルゴリズムである棄却サンプリングを試してみた
- 自己正規化重点サンプリング: 前提のお気持ちがわかりやすい
- PRML11章


密度比推定



Automatic Differentiation
Q: An application of Newton’s method for unconstrained minimization leads to updates of the form xk+1 = xk − H−1∇l(xk) where H is the hessian of l at xk. Ignoring the issue of computing the inverse, explain how you can combine the two modes of automatic differentiation to compute Hv efficiently for any vector v?
- Answer
- まずはじめに、Naive な実装で Backward Mode で Hv を計算しようとすると、Forward -> Backward, そこから、 Forward -> Backward を計算しなきゃいけない
- Forward Mode は 関数の評価とヤコビアンの計算を一回の Forward でやる (Activation の保持なし) ので、Backward Mode で必要な、二回分の Activation を保持する必要がない
- そのためメモリ効率がいいし、関数評価も早い
Reference
Assume N vertices/nodes, and let’s explore building up a DAG with maximum edges. Consider any given node, say N1. The maximum # of nodes it can point to, or edges, at this early stage is N-1. Let’s choose a second node N2: it can point to all nodes except itself and N1 - that’s N-2 additional edges. Continue for remaining nodes, each can point to one less edge than the node before. The last node can point to 0 other nodes.
Sum of all edges: (N-1) + (N-2) + .. + 1 + 0 == (N-1)(N)/2