Hiroki Naganuma
Q1. Overfitting, Capacity e.t.c.


Q2. Param and Hyperparam
Q3. Category of ML problems


k-menas法(k平均法)とは?
k-means法は、教師なし学習によるグループ分けの手法でした。教師なし学習でグループ分けを行うことを「クラスタリング」または「クラスター分析」と呼びます。
KNN(K近傍法)とは?
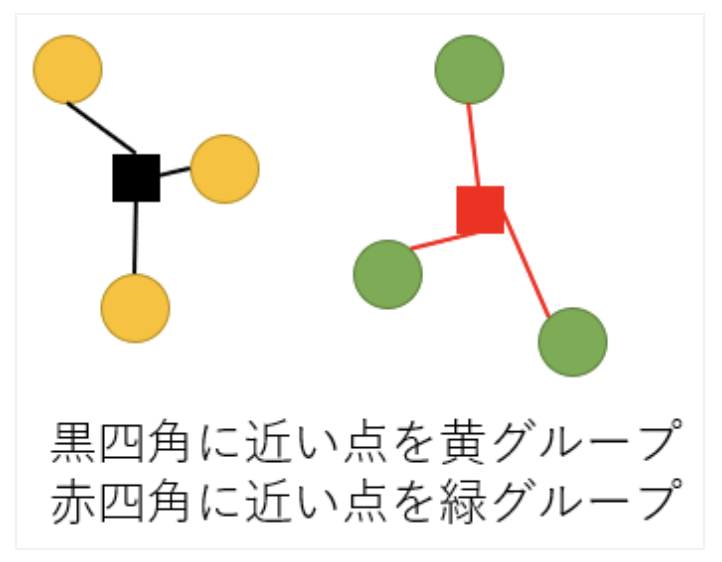
KNN(k-nearest neighbor)はK近傍法ともよばれる機械学習アルゴリズムです。アルゴリズムとしては非常に単純であり、「近くにあるデータは似ているはずだ」という発想に基づいています。 K近傍法のKは近くにあるデータをK個集めるという意味で、多数決により分類を決定します。
k近傍法とk平均法の違い 正解はk近傍法は教師あり学習なのに対してk平均法は教師なし学習だと言うことです。k近傍法は教師あり学習の中でも分類という学習に属し、k平均法は教師なし学習のなかのクラスタリングという学習に属します。分類とクラスタリングどちらも言葉が似ていますが、違いとして正解ラベルがあるかどうかです。
k近傍法



An easy to understand nonparametric model is the k-nearest neighbors algorithm that makes predictions based on the k most similar training patterns for a new data instance. The method does not assume anything about the form of the mapping function other than patterns that are close are likely to have a similar output variable. ノンパラメトリックモデルとしてわかりやすいのは、k-nearest neighborsアルゴリズムで、新しいデータインスタンスに対して、最も類似したk個の学習パターンに基づいて予測を行うものである。この方法は、近いパターンが類似の出力変数を持つ可能性が高いということ以外、マッピング関数の形式について何も仮定しない。
- An Introduction to Clustering and different methods of clustering
- Connectivity models:
- その名が示すように、データ空間において近いデータ点ほど、遠いデータ点よりも互いに類似性を示すという考え方に基づくモデルである。このモデルには2つのアプローチがある。最初のアプローチでは、すべてのデータ点を別々のクラスタに分類し、距離が小さくなるにつれてそれらを集約することから始める。2つ目のアプローチでは、すべてのデータ点を1つのクラスタとして分類し、距離が大きくなるにつれて分割していく。また、距離関数の選択は主観的なものである。これらのモデルは非常に解釈しやすいが、大きなデータセットを扱うためのスケーラビリティに欠ける。これらのモデルの例として、階層型クラスタリングアルゴリズム(Hierarchical Clustering)とその亜種がある。
- Centroid models: K-Means
- これらは反復的なクラスタリングアルゴリズムで、クラスタのセントロイドにデータ点が近いかどうかで類似性の概念を導き出すものである。K-Means クラスタリングアルゴリズムは、このカテゴリに分類される一般的なアルゴリズムである。これらのモデルでは、最後に必要なクラスタ数を予め述べておく必要があるため、データセットの事前知識が重要となる。これらのモデルは局所最適を見つけるために反復して実行される。
- Distribution models:
- これらのクラスタリングモデルは、クラスタ内のすべてのデータ点が同じ分布(例:正規分布、ガウス分布)に属する確率はどのくらいかという概念に基づいている。これらのモデルはしばしばオーバーフィッティングに悩まされる。これらのモデルの一般的な例として、多変量正規分布を使用する期待値最大化アルゴリズムがあります。
- Density Models:
- これらのモデルは、データ空間において、データ点の密度が変化している領域を探索する。様々な密度の異なる領域を分離し、これらの領域内のデータ点を同じクラスタに割り当てる。密度モデルの代表的な例として、DBSCANとOPTICSがある。
- Connectivity models:
Hierarchical Clustering
-
階層型クラスタリングは、その名が示すように、クラスタの階層を構築するアルゴリズムである。このアルゴリズムでは、まずすべてのデータ点をそれぞれのクラスタに割り当てる。次に、2つの最も近いクラスタが同じクラスタにマージされる。最終的に、1つのクラスタしか残らなくなった時点で、このアルゴリズムは終了する。 階層型クラスタリングの結果は、デンドログラムを用いて示すことができる。デンドログラムは次のように解釈できる。
- Hierarchical clustering¶
singlelinkage method
- データマイニング分野のクラスタリング手法 (1)
- ②(階層クラスター分析)

Hieralcical Method の中でも距離の計算を Ward 法や、 single linkage method で行う

